FAS论文阅读(一)
[toc]
Abstract
论文在开头指出,以前将基于深度学习的活体检测看作是一个二值问题,并致力于抓住伪装的特点,但是泛化性能往往很弱.本文着重于通过辅助监督的方法,帮助指导找出伪造活体的特点.通过一个CNN-RNN模型,对面部深度进行估计,监督逐个像素,以及rPPG信号.最终还提出一个包含大量不同光照、目标以及姿态的数据集.
Introduction
最早先的工作是基于纹理,输入指定的特征来进行二值化分类;后续使用到了卷积神经网络,利用softmax进行二分类.作者对于将活体检测视作二分类问题提出两个担忧:首先,对于伪造图像有着不同的层次的图像退化或称作伪造特点(如皮肤细节丢失,颜色失真,摩尔纹,变形),采用softmax loss的模型可能是基于任意一个特征进行的分类,例如相片的边框而非真实的伪造特点,当进行测试时如果没有了这些错误学习的特点,则会造成误判,其二,二值判断的网络模型不具备可解释性.
作者基于空间和时间两个角度来辅助判断,从空间角度来讲,面部具有深度,从时间的角度来讲,活体可以检测出rPPG信号而伪造攻击对象没有,
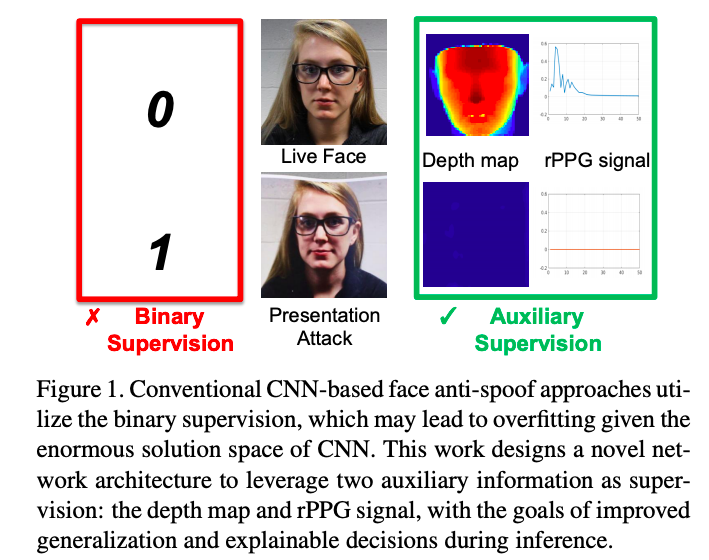
“To enable both supervisions, we design a network architecture with a short-cut connection to capture different scales and a novel non-rigid registration layer to handle the motion and pose change for rPPG estimation.”
考虑到数据的质量对模型训练同样重要的情况下,原先的CASIA、NUAA、Replay-Attack数据集时间已经过去很久,设备更新换代迅速,作者制作了一个数据集SiW,具有场景对象设备姿态多样化的特征.
Face Anti-Spoofing with Deep Network
Depth Map Supervision
对于给定的2D的image,利用dense face alignment(DeFA)估计出3D深度图