“面部遮挡与活体检测"
产生原因
- 物体(发型,口罩,围巾。。。)
- 姿势(头部或者身体)
- 光线遮挡
1.算法应该更多地依赖于没有遮挡的面部部位,然而,很难预测哪个面部部位或哪个面部关键点被遮挡
2.任意面部部分可能被任意形状和形状的物体所遮挡,面部关键点检测算法应具有足够的灵活性来处理不同的情况(例如,口罩遮住嘴巴,或者手遮住了鼻子等)
3.遮挡区域通常是局部一致的
检测中的挑战
- 面部信息不完整
- 遮挡面部信息的不准确性
解决方法
–>遮挡人脸识别传统方法
- 子空间回归(SVM和PCA):通过使用干净的训练样本从退化的图像或遮挡的图像中恢复干净的图像然后将重建的图像用于面部识别【可能会引入噪音】
- 鲁棒误差编码:“加法模型”,”乘法模型“
- 鲁棒特征提取:对面部特征进行分解,降低特征间相互干扰,
–>深度学习
- 对遮挡区域特征进行修复
- 设计和使用Attention(FAN)的机制去识别没有被遮挡的人脸:将不同大小的脸放到不同的特征层,增强人脸区域的特征,采取更多的数据
面部属性标注及遮挡类型定义
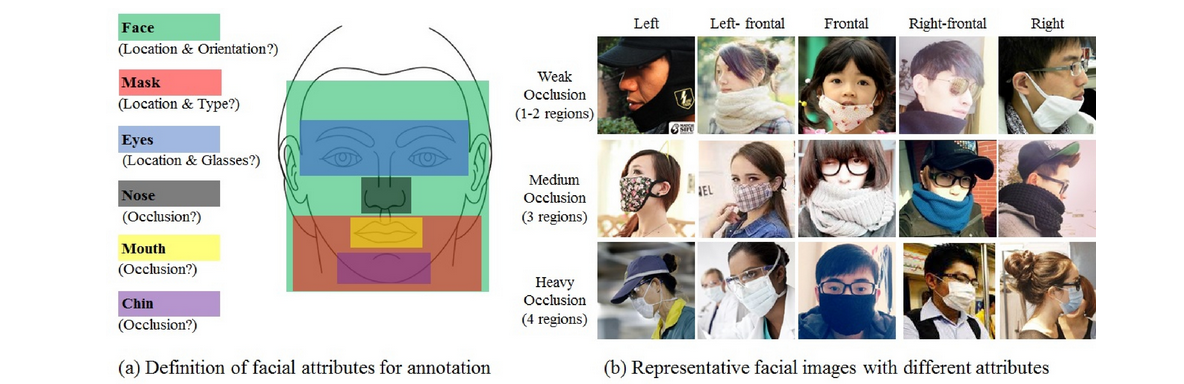
以及四个遮挡类型:
- Simple-mask简单涂色的人造面具
- Complex mask带有复杂纹理的人造面具
- Human body
- Hybrid mask上述几种的混合
方向
- 数据驱动
- 预测面部类型和遮挡度
数据集
补充环节
- PCA
PCA (主成分分析)一种简化数据集的技术。它是一个线性变换。这个变换把数据变换到一个新的坐标系统中,使得任何数据投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。主成分分析经常用减少数据集的维数,同时保持数据集的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。