“MobileNets_v3"
Searching for MobileNetV3
Network Architecture Search(NAS)
For MobileNetV3 we use platform-aware NAS to search for the global network structures by optimizing each network block
主要用于定义网络参数(层数,每层的算子,卷积核的大小,etc.)
通过基于和MnasNet相同的RNN的全局网络结构搜索和分解层次搜索空间,得到了Mobilenet_v3_Large(就是直接使用的Mnas-A1的网络结构)
But,这样得到的结构不适用于小型的移动设备,同时发现了对于小的模型来说,延迟会导致准确率极大的波动,于是调整了搜索的权重因子,得到了Mobilenet_v3_small
NetAdapt algorithm
We then use the NetAdapt algorithm to search per layer for the number of filters
- 首先利用NAS得到一个种子模型
- 对于每一步作如下操作:
- 采取一系列能使上一步的延迟至少减少δ的方案
- 对于每个方案,使用上一步的预训练模型,适当地截断和随机初始化丢失的权重。每个建议进行T步微调,以获得对精度的粗略估计。
- 通过一些矩阵选择最好的方案
- 迭代以上步骤直至达到目标延迟
note: 1. 上述矩阵作用是最小化准确率的波动,此算法希望能够不断减小准确率波动和延迟波动之间的比率直至达到目标延迟,在每一步方案的选择中选择∆Acc/∆Latency最大的那个,原因是基于直觉,由于每个方案都是离散的,所以选择曲线中斜率最大的
- 方案遵循以下两个原则:
- 减少expansion layer的大小
- 保留残差连接的情况下较少瓶颈层
网络提升
–>Redesigning Expensive Layers
- last few layers
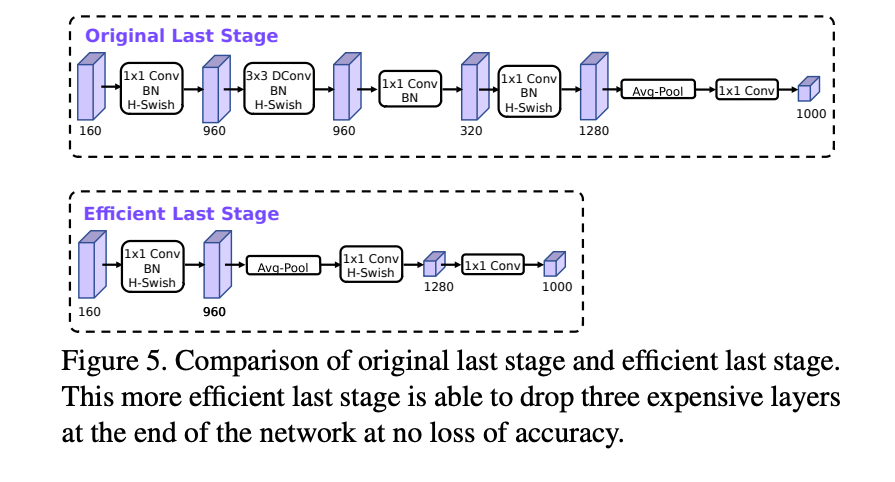
原先mobilenet-v2在网络的最后是将特征映射到高维空间,需要大量计算和一定的延迟,此处先不扩展到1280维,先池化在扩展,大大减少计算量且准确率没怎么变,而前一步于减少计算量的瓶颈层就可以全部去掉,同时几乎不怎么影响准确率。
- initial set of filters
通过实验和结合h-swish激活函数,将初始卷积核由原来32降低为16
–>Nonlinearities
- h-swish
A modified version of the recent swish nonlinearity, which is faster to compute and more quantization-friendly
swish x =x*Sigmoid(x)
就目前实验结果来看,准确率能少量提高,但是计算时间变长了,主要消耗在Sigmoid上,所以此处进行改进,将Sigmoid近似于ReLU6(x+3)/6,称改进后的损失函数为h-swish,经过实验表明,这样修改后精度基本上没什么变化,好处在于ReLU6可以在各种平台上进行运算,同时在量化的时候,消除了潜在的,由于Sigmoid不同表达形式而造成的精度损失,而且在越深的网络效果越明显
–>引入SE结构
Mobilenet_v2与Mobilenet_v3加上SE block比照:
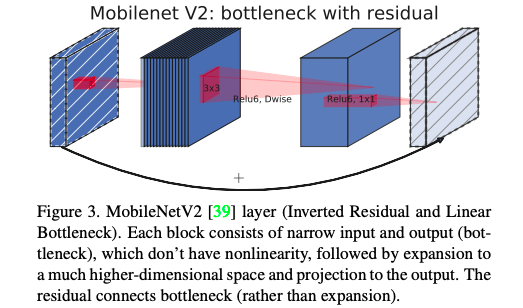
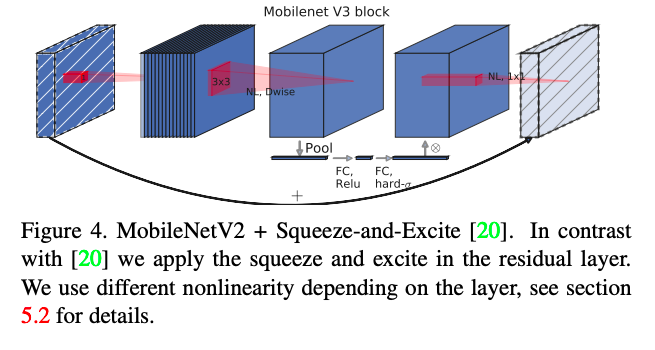
v3在DWConv后面加上了SE结构,是为了获得更大具有代表性的特征,同时使用改进过后的swish非线性函数连接在最后来代替Relu6
此处的SE模块里为了减少时间的消耗,将expansion layer 的通道变为原来的1/4,这样做提高了精度,同时没有增加延迟