“MobileNets_v2"
MobileNetV2: Inverted Residuals and Linear Bottlenecks
based on an inverted residual structure where the shortcut connections are between the thin bottleneck layers. 主要解决了V1在训练过程中非常容易特征退化的问题
Depthwise Separable Convolutions
略
Linear Bottlenecks
通常将数据可以看做数据流(manifold),是指可以将高维的数据映射到低维上,而低维的数据更方便计算。ReLU的作用是对维度进行压缩,但是当维度较低时,信息流无法分布到ReLU的激活带上,会造成较大的信息损耗(塌缩),当信息完全无法流过ReLU时,输出就是0,在反向传播中,0值的梯度为0,即梯度消失,发生了特征退化。
如下图所示,当原始输入维度数增加到15以后再加ReLU,基本不会丢失太多的信息;但如果只把原始输入维度增加至2~5后再加ReLU,则会出现较为严重的信息丢失,除非
imput manifold可以嵌入到激活空间的显著的低维子空间。

因此执行完降维的卷积后不会再使用ReLU
–> 比较Mobilenet_V1与Mobilenet_V2
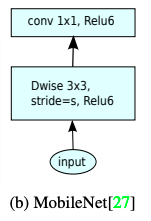
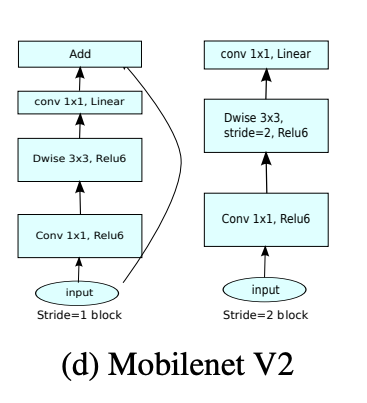
两个结论:
- 如果一个信息可以完整地通过一个非线性ReLU,这个激活层相当于一个线性激活层
- 仅当信息能够映射到低维子空间中的时候,ReLU激活才能不丢失数据
Inverted residuals
ResNet
本质就是降低数据中的冗余度
特征复用:提取数据中的identity部分,可以不用再让网络去学习一个identity mapping,而因为是直接从identity上学习残差,极大加快了模型的学习速度
对非冗余的数据采用线性激活(skip connection)获得无冗余的数据(identity),对冗余的数据,采取非线性激活,即对identity之外的信息进行提取和过滤(残差),
从数据中拿掉非冗余部分的identity部分,会导致余下数据的冗余度变高,那么再使用ReLU非线性激活的时候,丢失的有用信息也会减少,输出为0的可能降低,即降低梯度消失的概率,有利于网络的加深,极大发挥深度网络的潜能。
常规的residuals block因为没有使用DWConv,特征还是很多的,所以首先使用一个1✖️1的卷积降低通道数(即降低数据冗余程度),再通过卷积,最后重新用一个1✖️1的卷积将通道数扩张回去,此处倒置过来的意义在于DWConv本来就采集的特征很少了,所以,先使用1✖️1的卷积扩张通道,再进行DWConv,最后再把通道降回来。
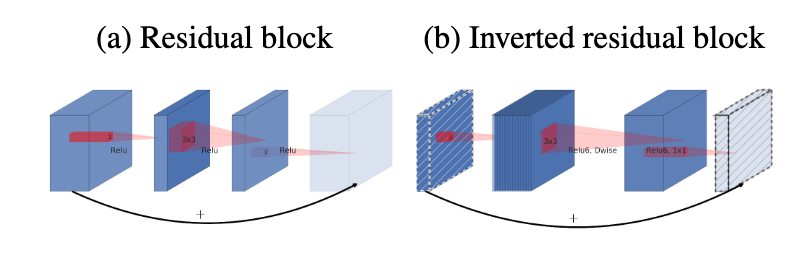
Some little things
- 除了最后Average层,全部结构基本上都是使用stride=2来进行下采样 池化下采样参数少(没有),而很多实验表明stride为2的卷积下采样效果更好
- short cut只对stride=1使用,stride=2不使用,是为了保证输入输出的维度相同