“MobileNets_v1"
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
构建非常小的低延迟模型,可以轻松地匹配移动和嵌入式视觉应用的设计要求:
- an efficient network architecture
- a set of two hyper-parameters
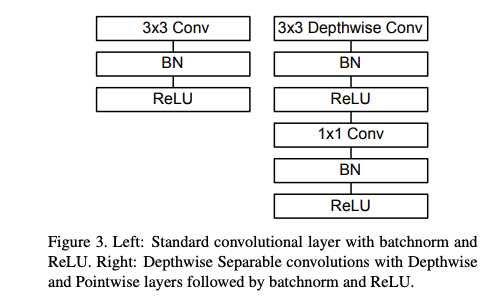
Depthwise Separable Convolution
首先它使用深度可分离的卷积来打破输出通道数量与内核大小之间的相互作用。将标准卷积分解为深度卷积和称为逐点卷积的1✖️1卷积
标准卷积的计算成本为
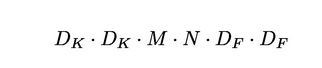
Dk是核的大小;Df是特征映射的大小;M是输入通道数;N是输出通道数
深度卷积每个输入通道应用单个卷积核,计算成本为:
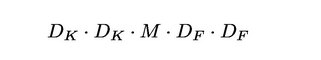
However it only filters input channels, it does not combine them to create new features.
所以接下来要使用1✖️1逐点卷积,计算成本比较:
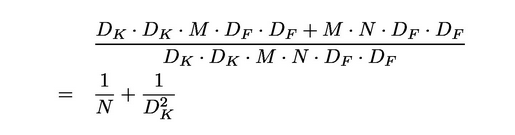
其中mobilenet使用的是3✖️3的卷积核,运算计算量和参数量比标准卷积小8至9倍,而精度降低很少
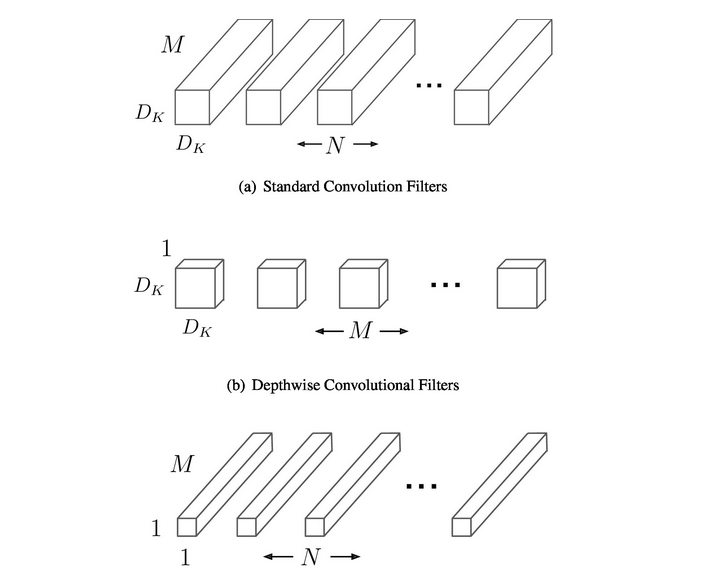
局部网络结构展示:
Width multiplier,α
- 该参数用于控制特征图的channel数量
- 对于depthwise卷积操作,其计算量为:
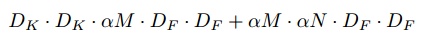
计算量和参数量大约减少了${α^2}$
Resolution multiplier,ρ
-
该参数用于控制特征图的宽和高。
-
对于depthwise卷积操作,其计算量为:
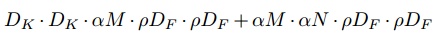
计算量和参数量大约减少了${ρ^2}$

遗留问题
-
结构问题:结构简单,直筒结构,性价比不高,后续一系列的ResNet, DenseNet等结构已经证明通过复用图像特征, 使用concat/eltwise+ 等操作进行融合, 能极大提升网络的性价比。
-
DWS问题:Depthwise 部分的kernel比较容易训废掉,训出来的kernel有不少是空的(Relu)
补充
1. 参数量和计算量、FLOPs
参数量是参与计算参数的个数,占用内存空间
若输入通道和输出通道
,则参数量为:
计算量(乘加次数),MAC(Multiply Accumulate),需要考虑输出map的大小,1个MAC算两次操作
输入通道和输出通道
,则计算量为:
浮点运算量,指计算量(floating point operations)
若考虑偏置:FLOPs=
不考虑偏置:FLOPs=
2.Xception–>Inception V3
3.GEMM
网络90%以上的运算都是集中在全连接层以及卷积层中,通常是通过GEMM,利用系统的多级存储结构和程序执行的局部性来充分加速运算。
- Why GEMM is at the heart of deep learning
- im2col方法,优化运算速度,减少运算时间